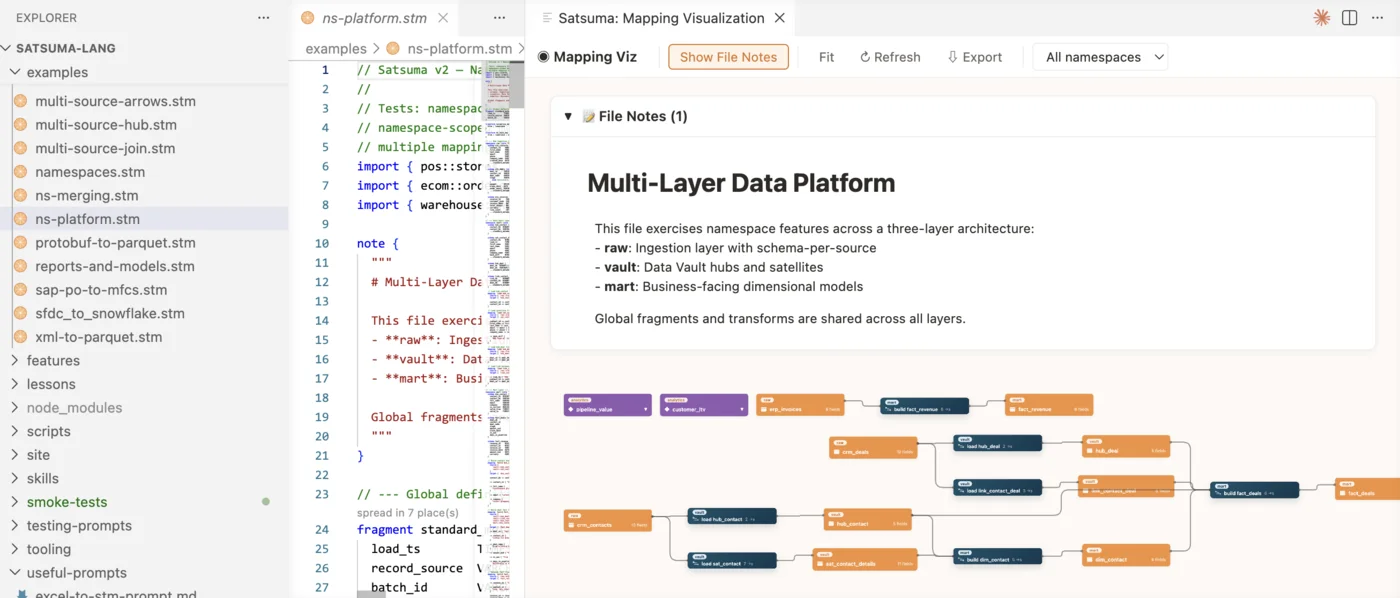
The mapping language humans can read, machines can parse, and AIs can reason about.
Replace spreadsheets and wikis with a single source of truth for source-to-target data mappings. Readable by product owners and business stakeholders, parseable by tooling, and AI-native by design.
customer_migration.stm
// Legacy Customer Migration
schema legacy_customers {
CUST_ID INT (pk)
CUST_TYPE CHAR(1) (enum {R, B, G})
EMAIL_ADDR VARCHAR(255) (pii) //! not validated
PHONE_NBR VARCHAR(50) //! mixed formats
COUNTRY_CD CHAR(2)
}
schema customers {
customer_id UUID (pk, required)
display_name VARCHAR(200) (required)
email VARCHAR(255) (format email, pii)
phone VARCHAR(20) (format E.164)
}
mapping `customer migration` {
source { `legacy_customers` }
target { `customers` }
CUST_ID -> customer_id { uuid_v5("6ba7b...", CUST_ID) }
EMAIL_ADDR -> email { trim | lowercase | validate_email }
-> display_name {
"If @CUST_TYPE is R or null, concat @FIRST_NM + @LAST_NM.
Otherwise use @COMPANY_NM. Trim and title-case."
}
PHONE_NBR -> phone {
"Extract digits. If 10 digits assume US +1.
For other patterns, determine country from @COUNTRY_CD."
| warn_if_invalid
}
}